딥러닝 훈련 도중 생기는 데이터 부족과 훈련 속도 문제에 대한 여러 가지 해결 방법을 정리해 보겠습니다.
*비지도 사전 훈련
레이블 된 훈련 데이터가 많지 않은 복잡한 문제가 있는데, 아쉽게도 비슷한 작업에 대해 훈련된 모델을 찾을 수 없다고 가정해 봅시다.
먼저 레이블 된 훈련 데이터를 더 많이 모아 봅시다.
이것이 어렵다면 비지도 사전 훈련(unsupervised pretraining)을 수행할 수 있습니다.
사실 레이블이 없는 훈련 샘플을 모으는 것은 비용이 적게 들지만 여기에 레이블을 부여하는 것이 비쌉니다.
레이블 되지 않은 훈련 데이터를 많이 모을 수 있다면 이를 사용하여 오토인코더나 생성적 적대 신경망과 같은 비지도 학습 모델을 훈련할 수 있습니다.
그런 다음 오토인코더나 GAN 판별자의 하위 층을 재사용하고 그 위에 새로운 작업에 맞는 출력 층을 추가할 수 있습니다.
그리고 레이블 된 훈련 샘플인 지도 학습으로 최종 네트워크를 세밀하게 튜닝합니다.
풀어야 할 문제가 복잡하고 재사용할 수 있는 비슷한 모델이 없으며 레이블 된 훈련 데이터가 적을 때는 비지도 사전 훈련이 좋은 선택입니다.
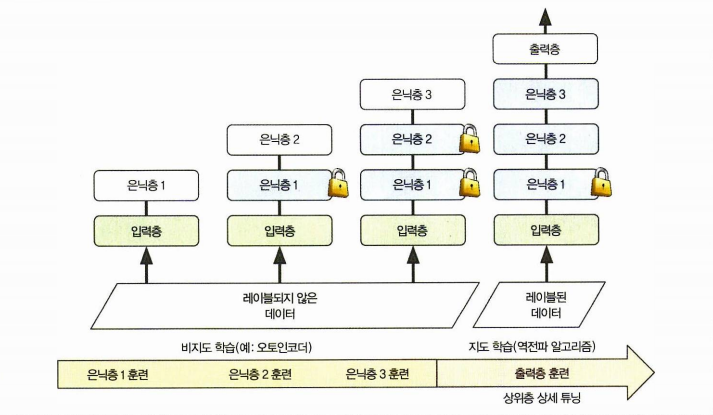
딥러닝 초기에는 층이 많은 모델을 훈련하는 것이 어려웠기 때문에 탐욕적 층 단위 사전 훈련이라고 부르는 기법을 사용했습니다.\
먼저 하나의 층을 가진 비지도 학습 모델을 훈련합니다.
일반적으로 RBM을 사용합니다.
그런 다음 이 층을 동결하고 그 위에 다른 층을 추가한 다음 모델을 다시 훈련합니다. (새로 추가한 층만 훈련하기 위해서!)
그다음 새로운 층을 동결하고 그 위에 또 다른 층을 추가하고 모델을 다시 훈련하는 식으로 반복됩니다.
오늘날에는 훨씬 간단한 방법을 사용합니다.
일반적으로 한 번에 전체 비지도 학습 모델을 훈련하고 RBM 대신 오토인코더나 GAN을 사용합니다.
*보조 작업에서 사전 훈련
레이블 된 훈련 데이터가 많지 않다면 마지막 선택 사항은 레이블 된 훈련 데이터를 쉽게 얻거나 생성할 수 있는 보조 작업에서 첫 번째 신경망을 훈련하는 것입니다.
그리고 이 신경망의 하위층을 실제 작업을 위해 재사용합니다.
첫 번째 신경망의 하위 층은 두 번째 신경망에 재사용될 수 있는 특성 추출기를 학습하게 됩니다.
예를 들어 얼굴을 인식하는 시스템을 만들려고 하는데 개인별 이미지가 얼마 없다면 좋은 분류기를 훈련하기에 충분치 않습니다.
각 사람의 사진을 수백 개씩 모으기란 현실적으로 어렵습니다.
그러나 인터넷에서 랜덤으로 많은 인물의 이미지를 수집해서 두 개의 다른 이미지가 같은 사람의 것인지 감지하는 첫 번째 신경망을 훈련할 수 있습니다.
이런 신경망은 얼굴의 특성을 잘 감지하도록 학습될 것입니다.
그러므로 이런 신경망의 하위 층을 재사용해 적은 양의 훈련 데이터에서 얼굴을 잘 구분하는 분류기를 훈련할 수 있습니다.
자연어 처리(NLP) 애플리케이션에서는 수백만 개의 텍스트 문서로 이루어진 말뭉치(CORPUS)를 다운로드하고 이 데이터에서 레이블 된 데이터를 자동으로 생성합니다.
예를 들면 일부 단어를 랜덤 하게 지우고 누락된 단어를 예측하는 모델을 만들 수 있습니다.
what __ you saying?이라는 문장에서 빠진 단어를 are 또는 were로 예측해야 합니다.
이 작업에서 좋은 성능을 내는 모델을 훈련할 수 있다면 언어에 대해 상당히 많은 것을 알고 있는 모델입니다.
실제 작업에 이 모델을 재사용하고 레이블 된 데이터를 사용하여 미세 튜닝할 수 있을 것입니다.
* 자기 지도 학습(self - supervised learning)은 위의 텍스트를 마스킹하는 예에서처럼 데이터에서 스스로 레이블을 생성하고 지도 학습 기법으로 레이블 된 데이터셋에서 모델을 훈련하는 방법입니다.
*고속 옵티마이저
아주 큰 심층 신경망의 훈련 속도는 심각하게 느릴 수 있습니다.
지금까지 훈련 속도를 높이는 네 가지 방법을 보았습니다.
연결 가중치에 좋은 초기화 전략 적용하기, 좋은 활성화 함수 사용하기, 배치 정규화 사용하기, 사전 훈련된 네트워크의 일부 재사용하기입니다.
훈련 속도를 크게 높일 수 있는 또 다른 방법으로는 표준적인 경사 하강법 옵티마이저 대신 더 빠른 옵티마이저를 사용할 수 있습니다.
아래에서는 인기 있는 옵티마이저인 모멘텀 최적화, 네스테로프 가속 경사, AdaGrad, RMSProp, Adam과 그 변형을 소개하도록 하겠습니다.
*패션 MNIST에서 옵티마이저를 테스트하는 간단한 함수를 만들어보자!
import tensorflow as tf
#MNIST 데이터셋 불러오기
(X_train, y_train), (X_valid, y_valid) = tf.keras.datasets.mnist.load_data()
#정규화 (0~1 범위)
X_train = X_train.astype("float32") / 255.0
X_valid = X_valid.astype("float32") / 255.0
#생성 함수
def build_model(seed=42):
tf.random.set_seed(seed)
return tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28]),
tf.keras.layers.Dense(100, activation='relu', kernel_initializer='he_normal'),
tf.keras.layers.Dense(100, activation='relu', kernel_initializer='he_normal'),
tf.keras.layers.Dense(100, activation='relu', kernel_initializer='he_normal'),
tf.keras.layers.Dense(10, activation='softmax')
])
#학습 함수
def build_and_train_model(optimizer, epochs=10):
model = build_model()
model.compile(loss='sparse_categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
return model.fit(X_train, y_train, epochs=epochs,
validation_data=(X_valid, y_valid))
*모멘텀 최적화
볼링공이 매끈한 표면의 완만한 경사를 따라 굴러간다고 해 봅시다.
처음에는 느리게 출발하지만 종단속도 (terminal velocity)에 도달할 때까지는 빠르게 가속될 것입니다.
이것이 모멘텀 최적화의 핵심 원리입니다.
반대로 표준적인 경사하강법은 경사가 완만해질 때는 작은 스텝으로 움직이고 경사가 가파를 때는 큰 스텝으로 이동합니다.
하지만 속도가 높아지지는 않습니다.
결과적으로 표준적인 경사하강법은 모멘텀 최적화보다 최저점에 도달하는 데 일반적으로 훨씬 느립니다.
경사 하강법은 가중치에 대한 비용 함수 J(θ)의 그레이디언트(∇θJ(θ))에 학습률 η를 곱한 것을 바로 차감하여 가중치를 θ를 갱신합니다.
공식은 θ - η∇θJ(θ)입니다.
이 식은 이전 그레이디언트가 얼마였는지 고려하지 않습니다.
국부적으로 그레이디언트가 아주 작으면 매우 느려질 것입니다.
모멘텀 최적화는 이전 그레이디언트가 얼마였는지를 상당히 중요하게 생각합니다.
매 반복에서 그레이디언트를 (학습률 η를 곱한 후) 모멘텀 벡터 m에 더하고 이 값을 빼는 방식으로 가중치를 계산합니다.
다시 말해 그레이디언트를 속도가 아니라 가속도로 사용합니다.
일종의 마찰 저항을 표현하고 모멘텀이 너무 커지는 것을 막기 위해 이 알고리즘에는 모멘텀이라는 새로운 하이퍼파라미터 β가 등장합니다.
이 값은 0 (높은 마찰 저항)과 1(마찰 저항 없음) 사이로 설정되어야 합니다.
일반적인 모멘텀 값은 0.9입니다.
* 모멘텀 알고리즘 <m <-- βm - η∇θJ(θ) θ <-- θ + m >
그레이디언트가 일정하다면 종단속도 (가중치를 계산하는 최대 크기)는 학습률 η를 곱한 그레이디언트에 1 / 1 - β을 곱한 것과 같음을 확인할 수 있습니다.
예를 들어 β = 0.9면 종단 속도는 그레이디언트와 학습률을 곱하고 다시 10을 곱한 것과 같으므로 모멘텀 최적화가 경사 하강법보다 10배 빠르게 진행됩니다.
이는 모멘텀 최적화가 경사 하강법보다 더 빠르게 평편한 지역을 탈출하게 도와줍니다.
특히 입력값의 스케일이 매우 다르면 비용 함수는 한쪽이 길쭉한 그릇처럼 됩니다.
경사 하강법이 가파른 경사를 꽤 빠르게 내려가지만 좁고 긴 골짜기에서는 오랜 시간이 걸립니다.
반면에 모멘텀 최적화는 골짜기를 따라 바닥에 도달할 때까지 점점 더 빠르게 내려갑니다.
배치 정규화를 사용하지 않는 심층 신경망에서 상위 층은 종종 스케일이 매우 다른 입력을 받게 됩니다.
모멘텀 최적화를 사용하면 이런 경우 큰 도움이 됩니다.
또한 이 기법은 지역 최적점을 건너뛰도록 하는 데도 도움이 됩니다.
* 모멘텀 때문에 옵티마이저가 최적값에 안정되기 전까지 건너뛰었다가 다시 돌아오고, 다시 또 건너뛰는 식으로 여러 번 왔다 갔다 할 수 있습니다.
이것이 시스템에 마찰 저항이 조금 있는 것이 좋은 이유입니다.
이는 이런 진동을 없애주고 빠르게 수렴되도록 합니다.
케라스에서 모델을 구현하는 것은 매우 쉽습니다.
SGD 옵티마이저를 사용하고 momentum 매개변수를 지정하고 기다리면 됩니다.
import tensorflow as tf
#데이터 로드
(X_train, y_train), (X_valid, y_valid) = tf.keras.datasets.mnist.load_data()
#정규화
X_train = X_train / 255.0
X_valid = X_valid / 255.0
#모델 생성 함수
def build_model(seed=42):
tf.random.set_seed(seed)
return tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28]),
tf.keras.layers.Dense(100, activation='relu', kernel_initializer='he_normal'),
tf.keras.layers.Dense(100, activation='relu', kernel_initializer='he_normal'),
tf.keras.layers.Dense(100, activation='relu', kernel_initializer='he_normal'),
tf.keras.layers.Dense(10, activation='softmax')
])
#모델 학습 함수
def build_and_train_model(optimizer):
model = build_model()
model.compile(loss='sparse_categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
return model.fit(X_train, y_train,
epochs=10,
validation_data=(X_valid, y_valid))
#모멘텀 SGD 옵티마이저
optimizer = tf.keras.optimizers.SGD(learning_rate=0.001, momentum=0.9)
#학습
history_momentum = build_and_train_model(optimizer)
모멘텀 최적화의 한 가지 단점은 튜닝할 하이퍼파라미터가 하나 늘어난다는 것입니다.
그러나 보통 모멘텀 0.9에서 잘 작동하며 경사 하강법보다 거의 항상 더 빠릅니다.
*네스테로프 가속 경사
모멘텀 최적화의 한 변형은 기본 모멘텀 최적화보다 거의 항상 더 빠릅니다.
네스테로프 가속 경사 (NAG)는 현재 위치가 θ가 아니라 모멘텀의 방향으로 조금 앞선 θ + βm에서 비용 함수의 그레이디언트를 계산하는 것입니다.
* 네스테로프 가속 경사 알고리즘: m <-- βm - η∇θJ(θ + βm) θ <-- θ + m
일반적으로 모멘텀 벡터가 최적점을 향하는 방향을 가리킬 것이므로 이런 변경이 가능합니다.
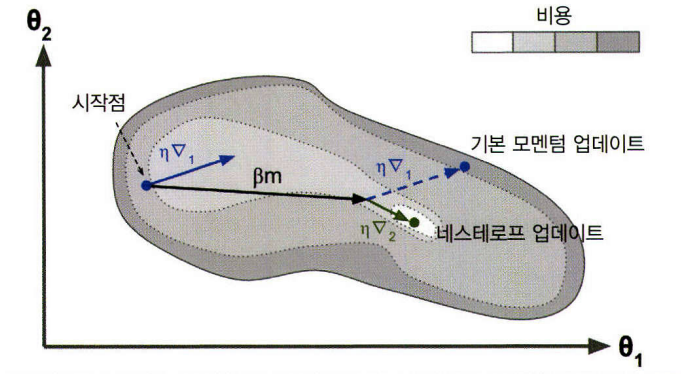
그래서 그림처럼 원래 위치에서의 그레이디언트를 사용하는 것보다 그 방향으로 조금 더 나아가서 측정한 그레이디언트를 사용하는 것이 더 정확할 것입니다.
- ∇1: 시작점 θ에서 측정한 비용 함수의 그레이디언트
- ∇2: θ + βm에서 측정한 그레이디언트
여기서 볼 수 있듯이 네스테로프 업데이트가 최적값에 더 가깝습니다.
시간이 조금 지나면 이 작은 개선이 쌓여서 NAG가 기본 모멘텀 최적화보다 확연히 빨라지게 됩니다.
더군다나 모멘텀이 골짜기를 가로지르도록 가중치에 힘을 가할 때 ∇1은 골짜기를 더 가로지르도록 독려하는 반면 ∇2는 계곡의 아래쪽으로 잡아당기게 됩니다.
이는 진동을 감쇠시키고 수렴을 빠르게 만들어 줍니다.
* 네스테로프 모멘텀을 계산하려면 현재 위치에서 가속도 방향으로 선진행하여 그레이디언트를 구해야 합니다.
실제로는 손쉬운 계산을 위해 조금 변형하여 구현되어 있습니다.
이 방식의 아이디어는 위 그림의 ∇2의 화살표 끝에서 βm의 화살표 끝으로 알고리즘의 이동 경로를 한 단계씩 뒤로 물러서 생각하는 것입니다.
이 두 지점은 확실히 차이가 있지만 알고리즘이 수렴하여 최적점에 가까워지면 거의 차이가 나지 않을 것입니다.
이 방식으로 수식을 풀어내면 네스테로프 알고리즘은 기본 모멘텀 방식을 두 번 중복 적용한 것으로 표현됩니다.
텐서플로우와 사이킷런도 이 방식을 사용하고 있습니다!
NAG을 사용하려면 SGD 옵티마이저를 만들 때 use_nesterov = True라고 설정하면 됩니다.
import tensorflow as tf
#모멘텀 SGD
optimizer = tf.keras.optimizers.SGD(
learning_rate=0.001,
momentum=0.9
)
*AdaGrad
한 쪽이 길쭉한 그릇 문제를 다시 생각해 봅시다.
경사 하강법은 전역 최적점 방향으로 곧장 향하지 않고 가장 가파른 경사를 따라 빠르게 내려가기 시작해서 골짜기 아래로 느리게 이동하고 있습니다.
알고리즘이 이를 일찍 감지하고 전역 최적점 쪽으로 좀 더 정확한 방향을 잡았다면 좋았을 것입니다.
AdaGrad 알고리즘은 가장 가파른 차원을 따라 그레이디언트 벡터의 스케일을 감쇠시켜 이 문제를 해결합니다.

첫 번째 단계는 그레이디언트의 제곱을 벡터 g에 누적합니다.
이 벡터화된 식은 벡터 g의 각 원소 Gi마다 Gi <= Gi + (∂J(θ) / ∂θ∂θi)^2를 계산하는 것과 동일합니다.
다시 말해 Gi는 파라미터 θi에 대한 비용 함수의 편미분을 제곱하여 누적합니다.
비용 함수가 i번째 차원을 따라 가파르다면 Gi는 반복이 진행됨에 따라 점점 커질 것입니다.
두 번째 단계는 경사하강법과 거의 같습니다.
한 가지 큰 차이는 그레이디언트 벡터를 √G+ε 으로 나누어 스케일을 조정하는 점입니다.
(ε은 0으로 나누는 것을 막기 위한 값으로 일반적으로 10^-10 임)
이 벡터화된 식은 모든 파라미터 θi에 대해 동시에 θi <= θi - η∂J(θ) / ∂θi / √Si+ε을 계산하는 것과 동일합니다.
요약하면 이 알고리즘은 학습률을 감쇠시키지만 경사가 완만한 차원보다 가파른 차원에 대해 더 빠르게 감쇠됩니다.
이를 적응적 학습률이라 부르며 전역 최적점 방향으로 더 곧장 가도록 갱신되는 데 도움이 됩니다.
학습률 하이퍼파라미터 η를 덜 튜닝해도 된다는 점은 또 하나의 장점입니다.

AdaGrad는 간단한 2차 방정식 문제에 대해서는 잘 작동하지만 신경망을 훈련할 때 너무 일찍 멈추는 경우가 있습니다.
학습률이 너무 감쇠하여 전역 최적점에 도착하기 전에 알고리즘이 완전히 멈춥니다.
그래서 케라스에 AdaGrad 옵티마이저가 있지만 심층 신경망에는 사용하지 말아야 합니다.
다만 선형 회귀 같은 간단한 작업에는 효과적일 수 있습니다.
하지만 AdaGrad를 알면 다른 적응적 학습률 옵티마이저를 이해하는데 도움이 됩니다.
* √Gi+ε으로 나눠지기 때문에 차원별로 학습률이 다르게 감소됩니다.
그레이디언트가 클수록 Gi도 커져 가파른 차원에서 학습률이 빠르게 감쇠되어 속도가 느려지고 완만한 차원에서는 진행이 빨라지는 효과를 냅니다.
* 케라스에서는 optimizer = keras.optimizers.Adagrad(learning_rate = 0.001)과 같이 사용합니다.
*RMSProp
AdaGrad는 너무 빨리 느려져서 전역 최적점에 수렴하지 못하는 위험이 있습니다.
RMSProp 알고리즘은 훈련 시작부터의 모든 그레이디언트가 아닌 가장 최근 반복에서 비롯된 그레이디언트만 누적함으로써 이 문제를 해결했습니다.
이렇게 하기 위해 알고리즘의 첫 번째 단계에서 지수 감쇠를 사용합니다.
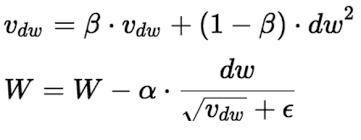
보통 감쇠율 ρ를 0.9로 설정하는 경우가 많습니다.
하이퍼파라미터가 하나 더 생겼습니다!
하지만 기본 값이 잘 작동하는 경우가 많으므로 이를 튜닝할 필요는 전혀 없습니다.
예상할 수 있듯이 케라스에는 RMSprop 옵티마이저가 있습니다.
optimizer = tf.keras.optimizers.RMSprop(learning_rate = 0.001, rho = 0.9)
아주 간단한 문제를 제외하고는 이 옵티마이저가 언제나 AdaGrad보다 훨씬 더 성능이 좋습니다.
사실 이 알고리즘은 Adam 최적화가 나오기 전까지 연구자들이 가장 선호하는 최적화 알고리즘이었습니다.
*Adam
적응적 모멘트 추정을 의미하는 Adam은 모멘텀 최적화의 RMSProp의 아이디어를 합친 것입니다.
모멘텀 최적화처럼 지난 그레이디언트의 지수 감쇠 평균을 따르고 RMSProp처럼 지난 그레이디언트 제곱의 지수 감쇠된 평균을 따릅니다.

이는 그레이디언트의 평균과 평균이 0이 아닌 분산에 대한 예측입니다.
이 평균을 첫 번째 모멘트라 부르고 분산은 두 번째 모멘트라 부르곤 해서 알고리즘의 이름이 적응적 모멘트 추정입니다.
t는 1부터 시작하는 반복 횟수를 나타냅니다.
식 1, 2, 5를 보면 Adam이 모멘텀 최적화, RMSProp과 아주 비슷하다는 것을 알 수 있습니다.
β1은 모멘텀 최적화의 β에 해당하고, β2는 RMSProp의 ρ에 해당합니다.
차이점은 식 1에서 지수 감쇠 합이 아닌 지수 감쇠 평균을 계산하는 것이지만 사실 상수 배인 것을 제외하면 동일합니다.
(지수 감쇠 평균은 지수 감쇠 합의 1- β1 배임)
식 3과 4는 기술적인 설명이 필요합니다.
m과 S가 0으로 초기화되기 때문에 훈련 초기에 0으로 치우치게 될 것입니다.
그래서 이 두 단계가 훈련 초기에 M과 S의 값을 증폭시키는 데 도움을 줍니다.
보통 모멘텀 감소 하이퍼파라미터 β1을 0.9로 초기화하고 스케일 감소 하이퍼파라미터 β2를 0.999로 초기화하는 경우가 많습니다.
앞에서처럼 안정된 계산을 위해 ε의 경우 보통 10^-7 같은 아주 작은 수로 초기화합니다.
이것이 Adam 클래스의 기본 값입니다.
* m과 s가 0부터 시작하므로 β1m과 β2s는 반복 초기에 크게 기여하지 못합니다.
식 3, 4는 이를 보상해 주기 위해 반복 초기에 m과 s를 증폭시켜 주지만 반복이 많이 진행되면 단계 3, 4의 분모는 1에 가까워져 거의 증폭되지 않습니다.
다음은 케라스에서 옵티마이저를 만드는 방법입니다.
optimizer = tf.keras.optimizers.Adam(learning_rate = 0.001 , beta_1 = 0.9 , beta_2 = 0.999)
Adam은 AdaGrad나 RMSProp처럼 적응적 학습률 알고리즘이기 때문에 학습률 하이퍼파라미터 η를 튜닝할 필요가 적습니다.
기본값 η = 0.001을 일반적으로 사용하므로 경사 하강법보다 Adam이 사용하기 더 쉽습니다.
마지막으로 Adam의 변형인 AdaMax, Nadam, AdamW를 살펴봅시다.
AdaMax는 Adam의 논문에서 소개되었습니다.
Adam의 식 2에서 Adam은 s에 그레이디언트 제곱을 누적합니다.
(최근 그레이디언트에 더 큰 가중치를 부여)
식 5에서 ε과 식 3, 4를 무시하면 Adam은 s의 제곱근으로 파라미터 업데이트의 스케일을 낮춥니다.
요약하면 Adam은 시간에 따라 감쇠된 그레이디언트의 L2 노름으로 파라미터 업데이트의 스케일을 낮추는 것입니다.(L2 노름은 제곱 합의 제곱근임)AdaMax는 L2 노름을 L 무한대 노름으로 바꿉니다.그래서 이름이 Max입니다.
구체적으로 Adam의 식 2를 s <= max(β2s , abs(∇θJ(θ)) 로 바꾸고 식 4를 삭제합니다.
식 5에서 s에 비례하여 그레이디언트 업데이트의 스케일을 낮춥니다.
시간에 따라 감소된 그레이디언트의 최대 절댓값입니다.
이 때문에 실전에서 AdaMax가 Adam보다 더 안정적입니다.
하지만 실제로 데이터셋에 따라 다르고 일반적으로 Adam의 성능이 더 낫습니다.
AdaMax는 어떤 작업에서 Adam이 잘 작동하지 않는다면 시도할 수 있는 옵티마이저입니다.
optimizer = tf.keras.optimizers.Adamax(learning_rate=0.001, beta_1=0.9, beta_2=0.999)
*AdamW
AdamW는 가중치 감쇠(weight decay)라는 규제 기법을 통합한 Adam의 변형입니다.
가중치 감쇠는 각 훈련 반복에서 모델의 가중치에 0.99와 같은 감쇠 계수 (decay factor)를 곱하여 가중치의 크기를 줄입니다.
이는 가중치를 작게 유지하는 것이 목표인 L2 정규화를 떠오르게 하며, 실제로 SGD를 사용할 때 L2 정규화가 가중치 감쇠와 동일하다는 것을 수학적으로 증명할 수 있습니다.
그러나 Adam 또는 그 변형을 사용할 때 L2 정규화와 가중치 감쇠는 동등하지 않습니다.
실제로 Adam과 L2 정규화를 결합하면 SGD로 만든 모델만큼 일반화되지 않는 모델이 생성됩니다.
AdamW는 Adam과 가중치 감쇠를 적절히 결합하여 이 문제를 해결합니다.
지금까지 논의한 모든 최적화 기법은 1차 편미분(야코비안)에만 의존합니다.
최적화 이론에는 2차 편미분(헤시안, 야코비안의 편미분)을 기반으로 한 뛰어난 알고리즘들이 있습니다.
불행하게도 이런 알고리즘은 심층 신경망에 적용하기가 매우 어렵습니다.
이런 알고리즘은 하나의 출력마다 n개의 1차 편미분이 아니라 n(파라미터 수)^2개의 2차 편미분을 계산해야 하기 때문입니다.
DNN은 전형적으로 수만 개 또는 그 이상의 파라미터를 가지므로 2차 편미분 최적화 알고리즘은 메모리 용량을 넘어서는 경우가 많고 가능하다고 해도 헤시안 계산은 너무 느립니다.
* 희소 모델 훈련: 지금까지 언급한 모든 최적화 알고리즘은 대부분의 파라미터가 0이 아닌 밀집 모델을 만듭니다.
엄청 빠르게 실행할 모델이 필요하거나 메모리를 적게 차지하는 모델이 필요하면 희소 모델을 만들 수 있습니다.
한 가지 방법은 보통 때처럼 모델을 훈련하고 작은 값의 가중치를 제거하기 위해 0으로 만드는 것입니다.
일반적으로 많이 희소한 모델을 만들지 못하고 모델의 성능을 낮출 수 있습니다.
더 좋은 방법은 훈련하는 동안 L1 규제를 강하게 적용하는 것입니다.
라쏘 회귀처럼 옵티마이저가 가능한 한 많은 가중치를 0으로 만들도록 강제합니다.
이런 기법이 잘 맞지 않는다면 텐서플로우 모델 최적화 툴킷 TF-MOT을 확인해 봅시다.
훈련하는 동안 반복적으로 연결 가중치를 크기에 맞춰 제거하는 가지치기 API를 제공합니다.
| 클래스 | 수렴 속도 | 수렴 품질 |
| SGD | * | *** |
| SGD (momentum = ...) | ** | *** |
| SGD (momentum = ..., nesterov=True) | ** | *** |
| Adagrad | *** | * (너무 일찍 멈춤) |
| RMSprop | *** | ** 또는 *** |
| Adam | *** | ** 또는 *** |
| AdaMax | *** | ** 또는 *** |
| Nadam | *** | ** 또는 *** |
| AdamW | *** | ** 또는 *** |
import tensorflow as tf
#MNIST 데이터 가져오기
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
#전처리
X_train = X_train.astype("float32") / 255.0
X_test = X_test.astype("float32") / 255.0
X_train = X_train.reshape(-1, 28, 28, 1)
X_test = X_test.reshape(-1, 28, 28, 1)
#모델 함수 정의
def build_and_train_model(optimizer):
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation="relu", input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation="relu"),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax")
])
model.compile(optimizer=optimizer,
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=5, batch_size=64,
validation_split=0.2)
return history, model
#AdamW 옵티마이저
optimizer = tf.keras.optimizers.AdamW(
weight_decay=1e-5,
learning_rate=0.001,
beta_1=0.9,
beta_2=0.999
)
#학습
history_adamw, model = build_and_train_model(optimizer)
#평가
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)
print(f"Test accuracy: {test_acc:.4f}")Epoch 1/5
750/750 ━━━━━━━━━━━━━━━━━━━━ 47s 60ms/step - accuracy: 0.8766 - loss: 0.4166 - val_accuracy: 0.9784 - val_loss: 0.0723
Epoch 2/5
750/750 ━━━━━━━━━━━━━━━━━━━━ 77s 54ms/step - accuracy: 0.9822 - loss: 0.0574 - val_accuracy: 0.9856 - val_loss: 0.0509
Epoch 3/5
750/750 ━━━━━━━━━━━━━━━━━━━━ 40s 53ms/step - accuracy: 0.9887 - loss: 0.0380 - val_accuracy: 0.9855 - val_loss: 0.0475
Epoch 4/5
750/750 ━━━━━━━━━━━━━━━━━━━━ 42s 55ms/step - accuracy: 0.9909 - loss: 0.0269 - val_accuracy: 0.9851 - val_loss: 0.0481
Epoch 5/5
750/750 ━━━━━━━━━━━━━━━━━━━━ 80s 53ms/step - accuracy: 0.9921 - loss: 0.0231 - val_accuracy: 0.9889 - val_loss: 0.0357
Test accuracy: 0.9896
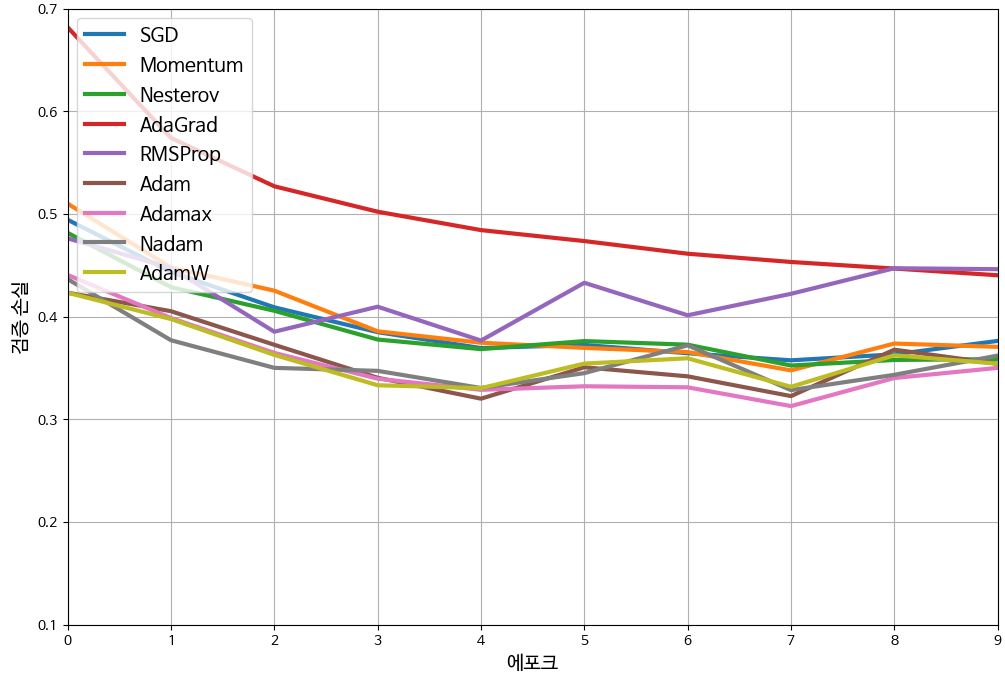
*모든 옵티마이저의 학습 곡선 시각화

'딥러닝 | 머신러닝' 카테고리의 다른 글
| 케라스를 활용한 심층 신경망: 과대적합 방지를 위한 딥러닝 규제 전략 4가지! (10) | 2025.08.24 |
|---|---|
| 케라스를 활용한 심층 신경망: 학습 안정화를 위한 스케줄링 전략! (2) | 2025.08.23 |
| 케라스를 활용한 심층 신경망: 그레이디언트 클리핑으로 학습 안정화 시키기! (7) | 2025.08.21 |
| 케라스를 활용한 심층 신경망: 배치 정규화로 학습 안정화 시키기! (1) | 2025.08.20 |
| 케라스를 활용한 심층 신경망: 활성화 함수와 심층 신경망 훈련! (12) | 2025.08.19 |